One Number, A Hundred Calls: A Spring Break Post on What Evaluation Actually Involves

Have you ever looked at an evaluation finding and wondered how it actually got there? How many decisions do you think went into that finding before it landed on your desk?
Behind every number in a report is a process full of decisions, trade-offs, and judgment calls that most people never see.
Today I want to walk you through the behind the scenes of evaluation findings. Findings in the form of percentages, statistical coefficients, effect sizes, cost ratios. Those numbers that show up in reports, presentations, and funding justifications.
What most people never see is everything that happened before that number existed.
I have been doing statistical analysis for program evaluation long enough to know that the hardest part is never the math. The hardest part is all the questions you have to answer before the math even starts.
Here is what most of the process involves:
Defining the question
Data collection and assembly
Data cleaning
Variable decisions
Model building
Testing model assumptions
Interpretation of results
Economic evaluation: when the analysis does not stop at impact
Each one of these is a step. Each step contains many little decisions. Let me walk you through what that actually looks like.
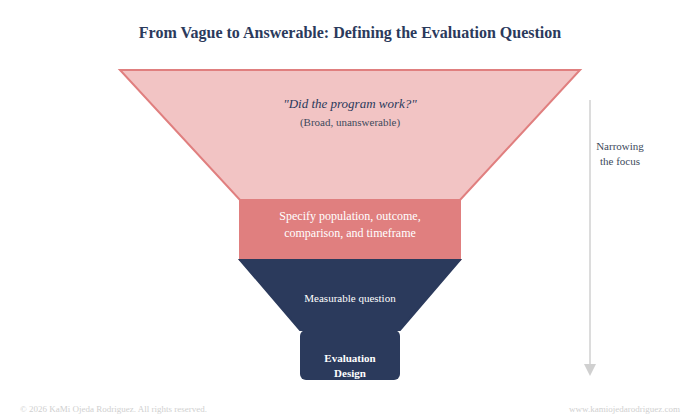
Defining the question
Before any analysis runs, someone has to decide what question the analysis is answering. That sounds obvious, right? What if I tell you, more often than we would’ve thought, program managers struggle to articulate the question they need an answer for in a way that leads to a solid evaluation project. The most frequent question I would get is "Did the program work?"; unfortunately, this is not an evaluation question. But if we ask, "Did students who received at least 30 hours of tutoring show greater gains in reading proficiency than comparable students who did not?" then the question is closer to get a real answer.
This initial question drives everything else in the evaluation process: from the method, the variables, the sample, the comparison, to the interpretation and ultimately the findings.
You might be surprised how a slight change to an evaluation question can lead to a completely different design.
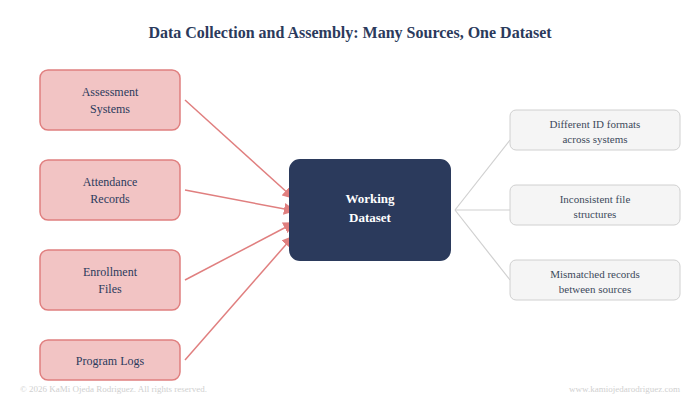
Data collection and assembly
Once the question is set, you need the right data to answer it. That means identifying every source: assessment systems, attendance records, enrollment files, program logs. Then it means pulling those sources together into a single working dataset, which almost never happens cleanly. Different systems use different student ID formats. Files are exported in inconsistent structures. Records from one source do not always match records from another. Assembling usable data takes time and precision before a single analysis step runs.
If you are lucky enough, you have some data in crazy formats that you just have to put together. Oftentimes, new data collection is needed and the process might get delayed a bit.
Data cleaning
Once we have the data, is time to do some cleanup because raw data is rarely (mostly never) ready to analyze. There are duplicate records, impossible values, missing entries, and inconsistent coding. A student listed as both enrolled and not enrolled in the same semester. A test score of 999 that is clearly a system default, or a 0 that does not mean the students does not know anything but perhaps something happened. Grade levels coded differently across years.
Every one of those issues requires a decision. Do you correct it, exclude it, or flag it? Each choice affects who ends up in your analysis and what the results reflect. So is within the data cleaning decision-making where the integrity of the analysis is either built or compromised.

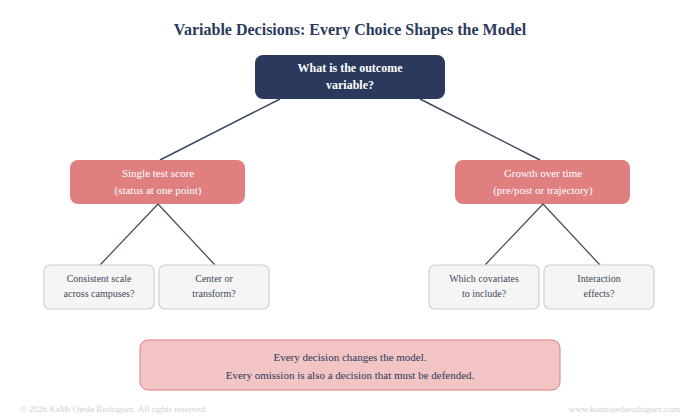
Variable decisions
Which variables do you include? Prior achievement, attendance, grade level, demographic characteristics. Each one you add changes the model. Each one you leave out is a choice you have to defend.
What about the outcome variable itself? Is a single test score the right measure, or do you need to look at growth over time? Are the scores consistent across campuses or did different schools use different assessments? Do variables need to be rescaled, centered, or transformed before the model runs? These are not small questions. They shape what your results can and cannot say.
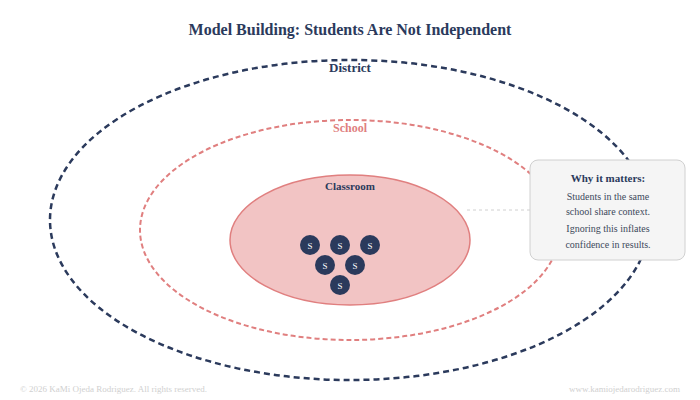
Model building
How do you handle the fact that students are grouped inside schools? A student in a high-performing school is not statistically independent from their classmates. Ignoring that structure inflates your confidence in the results. Accounting for it requires a different modeling approach entirely.
Are there interaction effects worth examining, meaning does the program work differently for different groups of students? Should the model be run separately by subgroup or does one model with interaction terms serve the question better? Every one of these is a fork in the road, and the path you choose has to be justified.
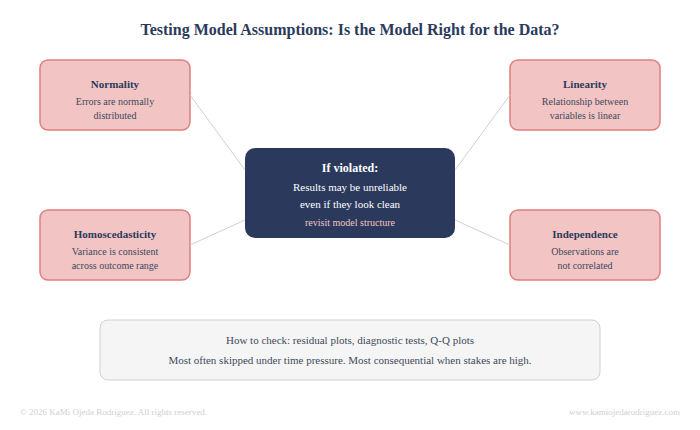
Testing model assumptions
Every statistical model rests on a set of assumptions about the data. That errors are normally distributed. That the relationship between variables is linear. That variance is consistent across the range of the outcome. That observations are independent. If those assumptions are violated, the model's results may be unreliable, even if they look clean on the surface.
Testing assumptions is the step that tells you whether the model you built is actually appropriate for the data you have. It involves looking at residual plots, running diagnostic tests, and sometimes going back to reconsider the model structure entirely. It is also the step most likely to be skipped when time is short, which is exactly why it matters so much when the stakes are high.
Interpretation of results
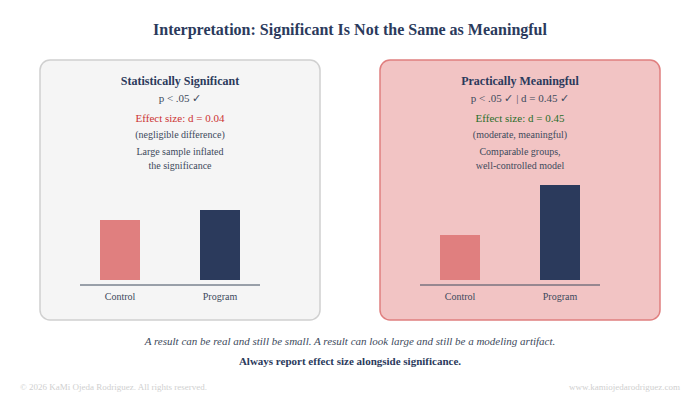
A statistically significant result does not automatically mean the program worked in a meaningful way. Effect size matters. Statistical power also matters. Whether the comparison group was truly comparable matters. Whether the outcome was measured at the right time matters.
A result can be real and still be small. A result can look large and still be the product of a poorly controlled model. Interpretation is where the analyst has to resist the pull toward a clean story and instead report what the evidence actually supports.
Economic evaluation: when the analysis does not stop at impact
For some of my evaluations, identifying the impact is not the finish line. It is the starting point for a different set of questions. Questions about whether the program was worth the investment, and how it compares to other ways the same dollars could have been spent.
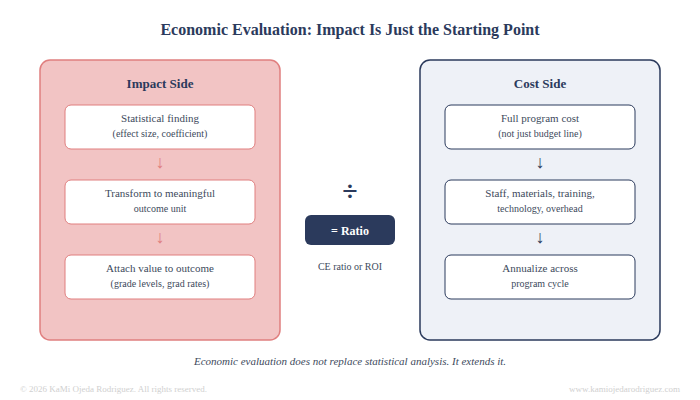
This is where economic evaluation begins. Once an impact estimate exists, it often needs to be transformed before it can be used in a cost analysis. A standardized effect size may need to be converted into a meaningful outcome unit. A gain score may need to be translated into something stakeholders can attach a value to, like grade level equivalents, projected graduation rates, or avoided costs downstream.
Then comes the cost side. What did the program actually cost? Not just the budget line, but the full accounting: staff time, materials, training, technology, overhead. Costs have to be identified, classified, and sometimes annualized across a program cycle before any comparison is possible.
From there, the analysis can take a different shape, like a cost-effectiveness ratio, which compares cost per unit of outcome, or a return on investment calculation, which converts outcomes into monetary terms and compares them directly to program costs. Each approach requires additional decisions about what counts, what gets excluded, and how uncertainty in the estimates is handled.
Economic evaluation extends impact analysis and adds another layer of decisions, transformations, and defensible choices that all have to hold up before a cost finding can be reported with any confidence.
So why does any of this matter to you?
Because when an evaluator hands you a report, you are not just receiving a number. You are receiving the outcome of dozens of judgment calls made by a person who had to balance rigor, available data, timeline, and the specific question your program needs answered.
Good evaluation is not a machine that processes data and produces truth. It is a disciplined process of asking the right questions, making defensible decisions, and being transparent about what the results can and cannot support.
The next time someone summarizes your program in a single statistic, it is okay to ask: how did we get there?
That question is evaluation literacy and it is the kind of question that leads to better programs.